CNN · Deep Residual
ResNet-50
50-layer residual network. Skip connections let gradients flow through deep stacks, making fine-grained texture features learnable.
81.1%
Test accuracy
Drop an image or snap one with your camera. Works best on a single, centered date with good lighting.
Step 1 · Upload
Step 2 · Result
Awaiting your image
The prediction, confidence breakdown, and heritage story will appear here.
Predicted Variety
Deep learning is not a black box here. Grad-CAM highlights the regions that shaped the prediction, and t-SNE projects the model's learned feature space into two dimensions.
Grad-CAM · Where the ViT looked
Warm regions show where the Vision Transformer attended most when forming its prediction. Upload an image above to see this per-image attention map.
Grad-CAM · Model Attention
Upload to see attention
Once you classify an image, Grad-CAM will overlay a heatmap showing the model's focus.
Heritage · About this variety
Season
—
How to spot it
—
Heritage · About this variety
Each Saudi date variety carries its own terroir — the oasis it grew in, the flavor profile that made it prized, and the role it plays in Saudi culture. Upload a date above to surface its story.
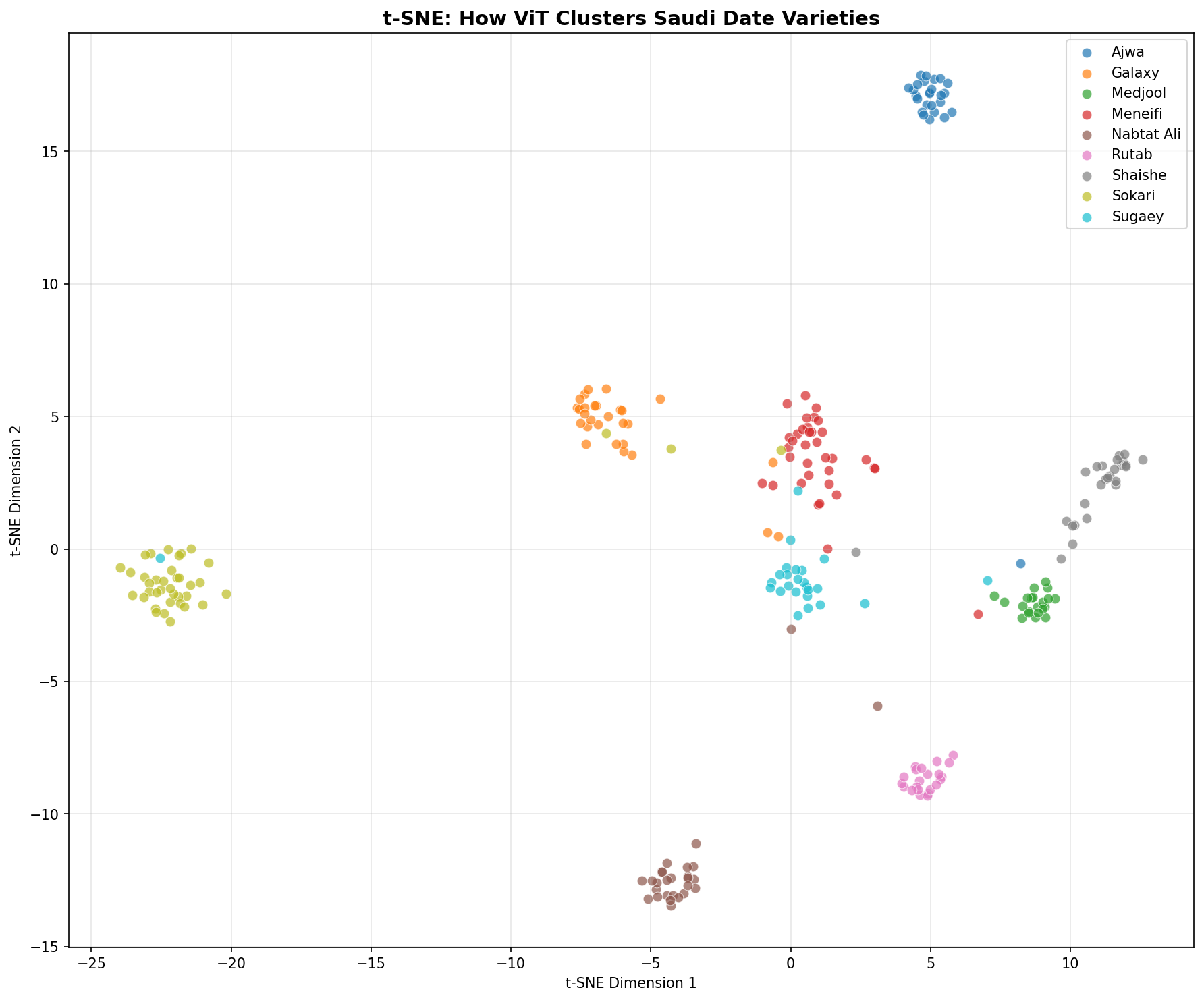
A 2-D map of Vision Transformer embeddings on the test set. Each point is one image; well-separated clusters mean the model has learned to distinguish varieties with clarity.
Saudi date harvests stretch from July through November. Hover or tap a variety to see its window. The brighter cell marks peak month.
Each architecture brings a distinct inductive bias. Their probabilities are averaged to produce the ensemble, which outperforms any single model on the held-out test set.
CNN · Deep Residual
50-layer residual network. Skip connections let gradients flow through deep stacks, making fine-grained texture features learnable.
Test accuracy
CNN · Compound Scaling
Depth, width, and resolution scaled in harmony. Fewer parameters than ResNet but sharper accuracy thanks to mobile inverted bottlenecks.
Test accuracy
Transformer · Self-Attention
Treats the image as a sequence of patches. Self-attention captures long-range dependencies — strong on subtle inter-variety differences.
Test accuracy